Bài 5: Giới thiệu về Pandas
![]()
1. Giới thiệu
1.1. Pandas là gì?
Pandas (viết tắt từ Panel Data - bảng dữ liệu) là thư viện mã nguồn mở phục vụ cho việc phân tích và xử lý dữ liệu trong Python, được phát triển bởi Wes McKinney trong năm 2008. Thư viện này được thiết kế để làm việc dễ dàng và trực quan với dữ liệu có cấu trúc (dạng bảng, đa chiều, ...) và dữ liệu chuỗi thời gian. Hiện nay, Pandas được sử dụng rộng rãi trong cả nghiên cứu lẫn phát triển các ứng dụng về khoa học dữ liệu.
Pandas trở thành thư viện yêu thích của những nhà phân tích dữ liệu bởi:
- Pandas phù hợp với nhiều loại dữ liệu khác nhau:
- Dữ liệu dạng bảng, như trong bảng SQL hoặc bảng tính Excel.
- Dữ liệu chuỗi thời gian theo thứ tự và không có thứ tự.
- Dữ liệu ma trận tùy ý với nhãn hàng và cột...
- Dễ dàng thao tác, phân tích, xử lý và trực quan hoá dữ liệu:
- Khả năng xử lý dữ liệu mất mát (NaN,...), nhiễu, ...
- Khả năng thay đổi kích thước: chèn và xóa cột, dòng
- Khả năng căn chỉnh dữ liệu tự động và rõ ràng
- Khả năng phân tách, gộp nối, chuyển đổi, định hình các tập dữ liệu 1 cách linh hoạt giúp cho việc tổng hợp và phân tích dữ liệu nhanh gọn, dễ dàng hơn.
- Khả năng tải và lưu trữ dữ liệu theo nhiều format khác nhau: .csv, .txt, .excel, .pkl, .hdfs5, ...
- Khả năng xử lí dữ liệu dạng chuỗi.
- Khả năng tích hợp tốt với các thư viện khác của Python: SciPy, Matplotlib, Seaborn, Plotly, Sklearn, ...
1.2. Cài đặt
- Cài đặt khi tạo môi trường ảo:
conda create -n hanh python=3.7 pandas
- Cài đặt sau khi tạo xong môi trường ảo:
conda install pandas
hoặc
pip install pandas
1.3. Import thư viện
import pandas as pd
Tham khảo:
2. Các hàm cơ bản trong Pandas
2.1. Objects trong Pandas
Trong Pandas, ta có 2 khái niệm:
- DataFrames: các bảng dữ liệu bao gồm nhiều hàng và nhiều cột, khởi tạo thông qua câu lệnh
pd.DataFrame() - Series: cột dữ liệu, khởi tạo thông qua câu lệnh
pd.Series()
Bảng dữ liệu trong SQL gọi là bảng, Excel gọi là sheet, còn Python gọi đây là 1 DataFrame của Pandas. Hiểu đơn giản, 1 cái Series là 1 cột của DataFrame. Ở mức máy tính thì Series là 1 object riêng và DataFrame là 1 object riêng. Tuy nhiên, có thể chuyển 1 Series thành DataFrame và chuyển DataFrame 1 cột thành Series.
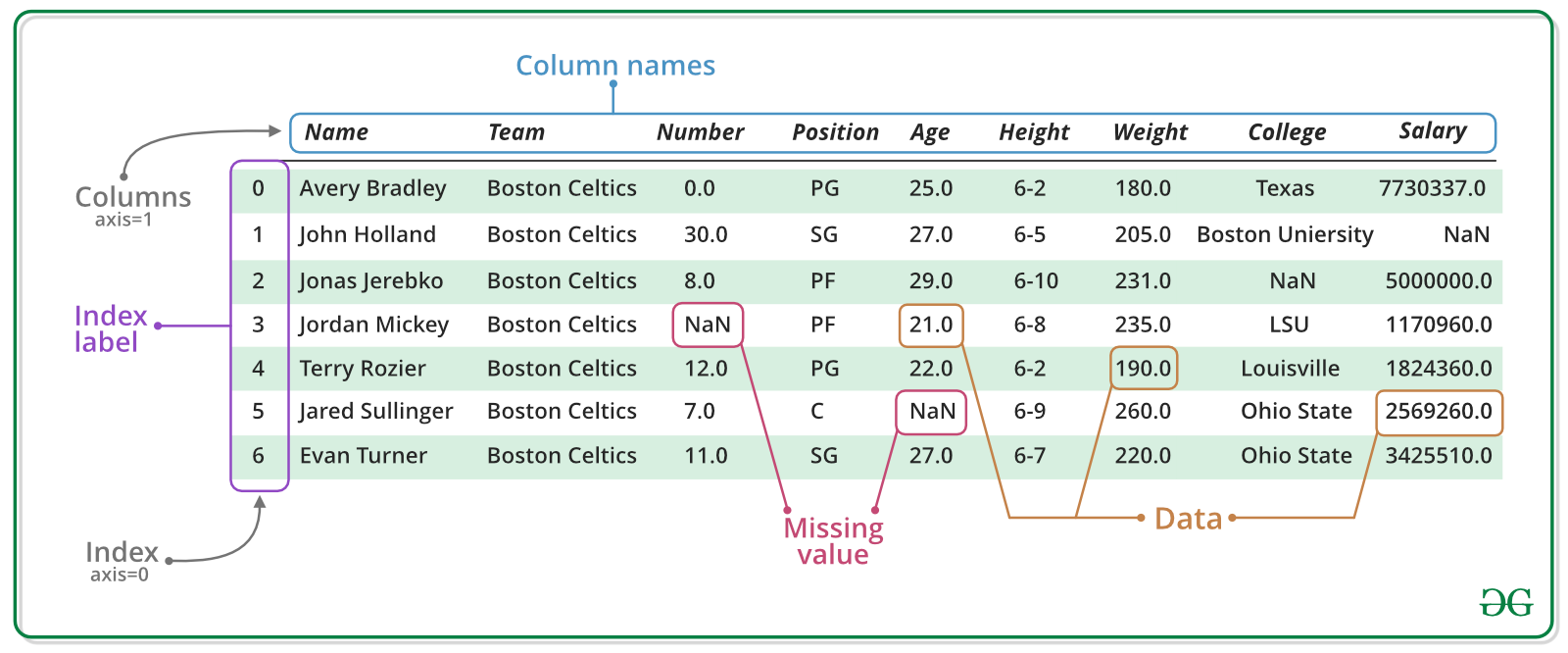

2.2. Khởi tạo 1 DataFrame
- Tạo ra 1 DataFrame rỗng
df = pd.DataFrame() #tạo ra 1 dataframe rỗng
type(df)
pandas.core.frame.DataFrame
Vậy trong trường hợp ta muốn tạo ra 1 DataFrame có chứa dữ liệu như dưới đây thì làm thế nào?
| name | age | university | |
|---|---|---|---|
| student1 | My | 10 | MIT |
| student2 | Hanh | 11 | Harvard |
| student3 | Long | 12 | NYU |
| student4 | Dat | 14 | Paris13 |
| student5 | Hoai | 15 | MCU |
- Tạo ra 1 DataFrame từ dict
dict1 = {'name':['My','Hanh', 'Long', 'Dat', 'Hoai'],
'age':[10,11,12,14,15],
'university':['MIT','Harvard','NYU','Paris13','MCU']}
df1 = pd.DataFrame(dict1, index=[f'student{i}' for i in range(1,6)])
- Tạo ra 1 DataFrame từ list của list
li = [['My',10,'MIT'], ['Hanh',11,'Havard'], ['Long',12,'NYU'],['Dat',14,'Paris13'],['Hoai',15,'MCU']]
df2 = pd.DataFrame(li, columns=['name', 'age', 'university'], index=[f'student{i}' for i in range(1,6)])
- Tạo ra 1 DataFrame từ zip
name = ['My','Hanh', 'Long', 'Dat', 'Hoai']
age = [10,11,12,14,15]
university = ['MIT', 'Harvard','NYU','Paris13','MCU']
tuple_li = list(zip(name, age, university))
df3 = pd.DataFrame(tuple_li,columns = ['name', 'age','university'], index=[f'student{i}' for i in range(1,6)])
- Tạo từ 1 chuỗi numpy
| col1 | col2 | col3 | col4 | |
|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 |
| 1 | 5 | 6 | 7 | 8 |
| 2 | 9 | 10 | 11 | 12 |
| 3 | 13 | 14 | 15 | 16 |
import numpy as np
df1 = pd.DataFrame(np.linspace(1,16,16).reshape(4,4), columns=['col1', 'col2','col3', 'col4'])
df1 = pd.DataFrame(np.linspace(1,16,16).reshape(4,4), columns=[f'col{i}' for i in range(1,5)])
2.3. Khởi tạo 1 Series
#Lấy các giá trị 1 cột trong DataFrame và truyền vào biến Series
series = df2['name'] # cách 1
series = df2.name # cách 2
Đố vui: Vì sao trong Pandas lại có 2 cách khác nhau để gọi 1 cột trong DataFrame?
Ngoài ra, có 1 số cách để ta khởi tạo 1 Series như dưới đây"
series1 = pd.Series({'name':[1,2,3]}) #khởi tạo 1 Series tên name và có các giá trị 1,2,3
Để trả về 1 Series có tên là Zoo có giá trị ['Z','o','o'] tương ứng index là ['Char1','Char2','Char3'].
Ta có thể chọn 1 trong 2 cách dưới đây.
series2 = pd.Series(['Z','o','o'], index=['Char1', 'Char2','Char3'], name='Zoo')
series3 = pd.Series(np.array(['Z','o','o']), index=['Char1', 'Char2','Char3'], name='Zoo')
2.4. Đọc/lưu 1 DataFrame
Pandas hỗ trợ đọc nhiều format dữ liệu khác nhau, ví dụ như: excel, csv, sql, html, json, table, ... Ở đây, mình sẽ ví dụ với 1 kiểu dữ liệu được sử dụng phổ biến nhất, đó là .csv. csv là viết tắt của cụm từ commas seperated value, về bản chất là 1 file text lưu trữ các thông tin dạng bảng với các giá trị từng cột phân cách nhau bới dấu commas, tức là dấu phẩy. Có nhiều biến thể của file .csv, ví dụ .tsv tương ứng tab seperated value, ...
Ta có thể đọc file csv thông qua câu lệnh pd.read_csv() và lưu file tạo ra và thao tác thông qua câu lệnh pd.to_csv(). Tương tự như csv, các format dữ liệu khác cũng sẽ có cấu trúc câu lệnh trong Pandas tương tự như với csv. Dưới đây là 1 số ví dụ về đọc và lưu file với Pandas.
df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data', header=None) #dữ liệu online
import seaborn as sns
tips_df = sns.load_dataset('tips') #dữ liệu từ github của seaborn.
Trong bài học tiếp theo, chúng ta sẽ cùng nhau tìm hiểu 1 số hàm phổ biến giúp cho Pandas trở thành công cụ xử lý dữ liệu cấu trúc dạng bảng hàng đầu khi làm việc với Python.