Bài 6: Giới thiệu về Pandas (tiếp theo)
![]()
1. Tổng quan
Để hiển thị hết các dòng và các cột của 1 DataFrame hoặc 1 Series, ta có thể tận dụng câu lệnh dưới đây:
pd.options.display.max_rows =
None
pd.options.display.max_columns = None
hoặc
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
Để thuận tiện cho việc phân tích dữ liệu thông qua các hàm cơ bản Pandas hỗ trợ, ta sử dụng dữ liệu tips trong buổi trước, có format như sau:
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.5 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
import pandas as pd # import thư viện pandas để phân tích dữ liệu
import seaborn as sns # import thư viện seaborn để load dữ liệu
tips_df = sns.load_dataset('tips')
2. Các hàm cơ bản
2.1. Indexing
Ở phần trước, chúng ta đã nắm được cách khởi tạo 1 DataFrame hoặc 1 Series trong Pandas cũng như cách ta có thể đọc 1 file từ trên mạng và trong máy của bạn.
Vậy nếu muốn truy cập vào 1 phần tử cụ thể trong DataFrame hoặc Series thì ta phải làm như thế nào?
Để làm được điều này, Pandas có hỗ trợ:
[]: chọn các cột trong DataFrame và trả về 1 Series.
Chọn tất cả các dòng (slicing):
loc(location):df.loc[row_label,col_label],series.loc[row_label]locnhận tên của các hàng và cột, và trả về 1 Series hoặc DataFrame. Ta có thể sử dụnglocđể lấy toàn bộ hàng hoặc cột, cũng như các phần nhỏ của chúng.iloc(index location):df.iloc[row_index,col_index],series.iloc[row_index]ilocnhận các index của các hàng và cột, và trả về 1 Series hoặc DataFrame. Tương tự nhưloc, ta có thể sử dụnglocđể lấy toàn bộ hàng hoặc cột, cũng như các phần nhỏ của chúng.
Chọn 1 cell:
at:df.at[row_label,col_label]atnhận tên của các hàng và cột, và trả về một giá trị dữ liệu duy nhất.iat:df.iat[row_index,col_index]iatnhận index của các hàng và cột, và trả về một giá trị dữ liệu duy nhất.
Thực hành: Lấy giá trị ở hàng thứ 2 cột total_bill (10.34) trong tips_df
tips_df.loc[1,'total_bill']
10.34
tips_df.iloc[1,0]
10.34
tips_df.at[1,'total_bill']
10.34
tips_df.iat[1,0]
10.34
Thực hành: Lấy DataFrame dưới đây từ tips_df:
| total_bill | tip | sex | |
|---|---|---|---|
| 0 | 16.99 | 1.01 | Female |
| 1 | 10.34 | 1.66 | Male |
| 2 | 21.01 | 3.5 | Male |
| 3 | 23.68 | 3.31 | Male |
| 4 | 24.59 | 3.61 | Female |
| 5 | 25.29 | 4.71 | Male |
tips_df.loc[:5,:'sex'] # bao gồm tên cột, hàng bắt đầu và bao gồm tên cột, hàng kết thúc
tips_df.iloc[:6,:3] #bao gồm index bắt đầu, không bao gồm index kết thúc
Thực hành: Lấy hết thông tin của bảng ghi đầu tiên trong tips_df
| 0 | |
|---|---|
| total_bill | 16.99 |
| tip | 1.01 |
| sex | Female |
| smoker | No |
| day | Sun |
| time | Dinner |
| size | 2 |
| wow | nan |
tips_df.loc[0,] #tips_df.loc[0]
tips_df.iloc[0,] #tips_df.iloc[0]
Thực hành: Lấy tất cả các thông tin cột total_bill trong tips_df và ép định dạng về DataFrame.
tips_df['total_bill'].to_frame() # cách 1
pd.DataFrame(tips_df['total_bill']) # cách 2
tips_df[['total_bill']] # cách 3
Bài tập: Lấy DataFrame dưới đây trong tips_df.
| total_bill | tip | sex | smoker | day | time | |
|---|---|---|---|---|---|---|
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner |
tips_df.loc[3:4,:'time'] # cách 1
tips_df.iloc[3:5,:6] # cách 2
Bài tập: Lấy 5 dòng đầu của 2 cột sex và total_bill trong tips_df.
tips_df[['sex','total_bill']].head(5) # cách 1
tips_df.loc[:4,['sex','total_bill']] # cách 2
tips_df.iloc[:5,[2,0]] # cách 3
2.2. Masking/Filtering
Trong thực tế, đối với 1 tập dữ liệu có cấu trúc, đôi khi ta muốn lọc dữ liệu theo 1 số tiêu chí nhất định nhằm đáp ứng nhu cầu bài toán đề ra, ví dụ phân tích tập khách hàng nữ, phân tích tập khách hàng V.I.P có hoá đơn cao hơn 1 mức nhất định, hay tổng hợp và chỉ trích xuất dữ liệu trong 1 khoảng thời gian cần để phân tích. Để đáp ứng nhu cầu trên, Pandas có 1 số cách phổ biến như sau:
- Sử dụng cấu trúc
df_name.loc[conditions] - Sử dụng cấu trúc
df_name[conditions] - Sử dụng hàm
query().
Thực hành: Lọc tất cả các thông tin của những khác hàng là nữ trong tips_df
tips_df.loc[tips_df['sex'] == 'Female'] # cách 1
tips_df[tips_df['sex'] == 'Female'] # cách 2
tips_df.query("sex == 'Female'") # cách 3
Thực hành: Lọc tất cả các thông tin của những khác hàng là nữ có hút thuốc trong tips_df
tips_df[(tips_df['sex'] == 'Female') & (tips_df['smoker'] == 'Yes')] # cách 1
tips_df.loc[(tips_df['sex'] == 'Female') & (tips_df['smoker'] == 'Yes')] # cách 2
tips_df.query("sex == 'Female' & smoker == 'Yes'") # cách 3
Bài tập:
- Lọc tất cả các bản ghi chứa thông tin của khách hàng nam có tổng hoá đơn lớn hơn 10.
- Lọc tất cả các bản ghi chứa thông tin của khách hàng không hút thuốc và dùng suất ăn cho 3 người trở lên.
- Lọc tất cả các bản ghi chứa thông tin của khách hàng nữ ăn tối tại nhà hàng vào cuối tuần (Thứ 7, Chủ nhật) và tip cho nhân viên từ 5 đô trở lên.
Bài giải:
- Lọc tất cả các bản ghi chứa thông tin của khách hàng nam có tổng hoá đơn lớn hơn 10.
condition1 = (tips_df['sex'] == 'Male') & (tips_df['total_bill'] > 10)
tips_df[condition1] # cách 1
tips_df.loc[condition1] # cách 2
tips_df.query("sex == 'Male' & total_bill > 10") # cách 3
- Lọc tất cả các bản ghi chứa thông tin của khách hàng không hút thuốc và dùng suất ăn cho 3 người trở lên.
condition2 = (tips_df['smoker'] == 'No') & (tips_df['size'] >=3)
tips_df[condition2] # cách 1
tips_df.loc[condition2] # cách 2
tips_df.query("smoker == 'No' & size >= 3") # cách 3
- Lọc tất cả các bản ghi chứa thông tin của khách hàng nữ ăn tối tại nhà hàng vào cuối tuần (Thứ 7, Chủ nhật) và tip cho nhân viên từ 5 đô trở lên.
condition3 = (tips_df['sex'] == "Female") & (tips_df['time'] == "Dinner") & ((tips_df['day'] == "Sat") | (tips_df['day'] == "Sun")) & (tips_df['tip'] >=5)
tips_df[condition3] # cách 1
tips_df.loc[condition3] # cách 2
tips_df.query("(sex == 'Female') & (time == 'Dinner') & ((day == 'Sat') | (day == 'Sun')) & (tip >= 5)") # cách 3
2.3. Tổng hợp dữ liệu (Aggregation)
2.3.1 Groupby()
Trong Python, groupby() là một hàm linh hoạt trong Python cho phép bạn chia dữ liệu thành các nhóm riêng biệt để thực hiện các phép tính nhằm phân tích tốt hơn, cũng hoàn toàn tương tự như groupby trong SQL.
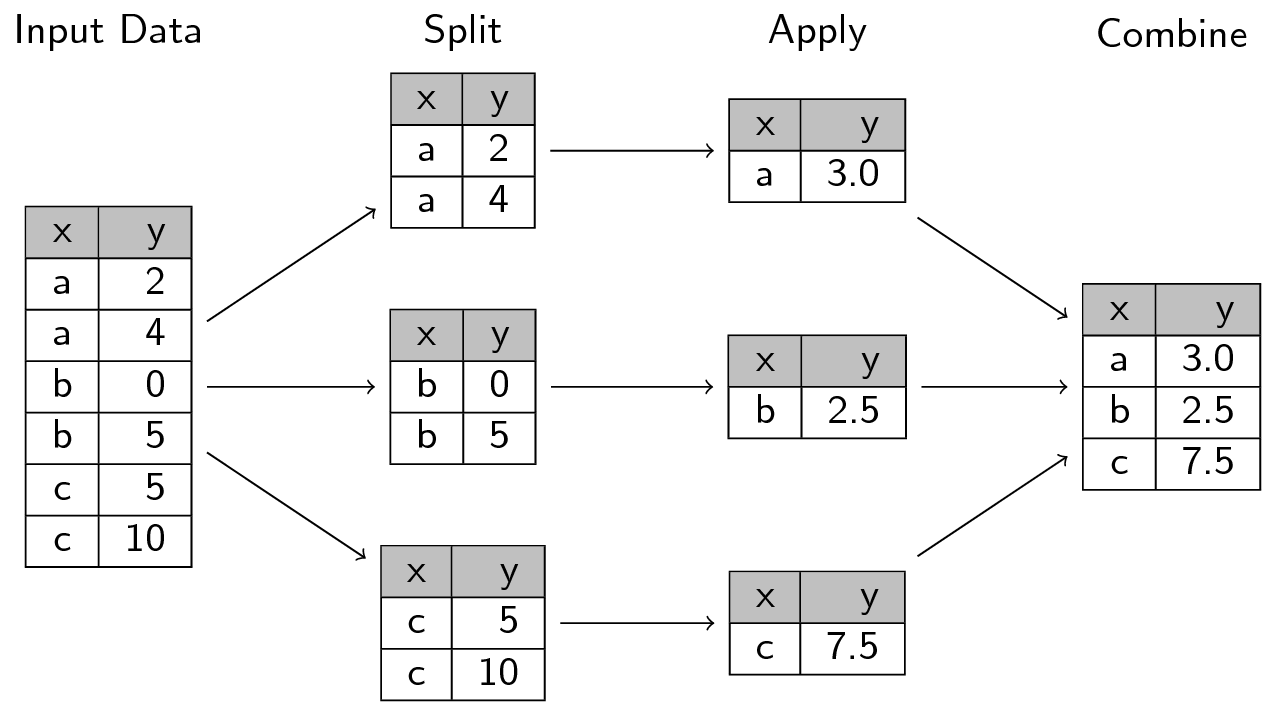
groupby() được xây dựng theo cơ chế 3 bước:
- Split: Chia dữ liệu thành các nhóm dựa trên một số tiêu chí (ví dụ theo cột
xtrong ảnh mô tả ở dưới) - Apply: Áp dụng một số phép tính toán cho từng nhóm một cách độc lập (ví dụ tính tổng các giá trị của từng nhóm trong cột
x). Bước này có thể là 1 trong các thao tác dưới đây:- Tổng hợp (Aggregation/Reduction): đưa ra 1 số phân tích thống kê trong một nhóm như sum, mean, std, min, max, size, count ... của nhóm dữ liệu.
- Chuyển đổi (Transformation): thực hiện một số tính toán nhóm như chuẩn hoá, lấp đầy các giá trị null ...
- Lọc (Filteration): loại bỏ một số nhóm, ...
- Combine: Kết hợp các kết quả vào một cấu trúc dữ liệu.
Pandas hỗ trợ 13 chức năng tổng hợp sử dụng sau groupby() sau:
| Tên hàm | Ý nghĩa |
|---|---|
mean() | Tính trung bình của các nhóm |
sum() | Tính tổng các giá trị của nhóm |
size() | Tính kích thước nhóm |
count() | Tính toán số lượng nhóm |
std() | Độ lệch chuẩn của các nhóm |
var() | Tính toán phương sai của các nhóm |
sem() | Sai số chuẩn của giá trị trung bình của các nhóm |
describe() | Tạo thống kê mô tả |
first() | Tính toán giá trị đầu tiên của nhóm |
last() | Tính giá trị cuối cùng của nhóm |
nth() | Lấy giá trị thứ n hoặc một tập hợp con nếu n là một danh sách |
min() | Tính toán giá trị nhỏ nhất nhóm |
max(): | Tính toán giá trị lớn nhất nhóm |
Thực hành: Tính trung bình số tiền mỗi giới tính trả khi ăn tại nhà hàng theo thống kê trong tips_df.
tips_df.groupby('sex').total_bill.mean() # riêng hoá đơn
tips_df['total_bill_tip'] = tips_df['total_bill'] + tips_df['tip'] #cả hoá đơn và tips
tips_df.groupby('sex').total_bill_tip.mean()
Thực hành: Tính số tiền lớn nhất, nhỏ nhất và trung bình hoá đơn và số tiền tips mỗi giới tính chi ra cho 1 bữa ăn tại nhà hàng theo thống kê trong tips_df.
tips_df.groupby('sex').agg({'total_bill':['mean','min','max'],'tip':['mean','min','max']})
# Ta có thể đổi tên cột bằng cách dưới đây
tips_df.groupby('sex').agg(mean_total_bill=('total_bill','mean'), mean_total_tip=('tip','mean'))
Thực hành: Tính số tiền trung bình trong hoá đơn và tips mỗi giới tính khi có hút thuốc và không hút thuốc chi ra cho 1 bữa ăn tại nhà hàng theo thống kê trong tips_df.
tips_df.groupby(['sex','smoker'])[['total_bill','tip']].mean()
Thực hành: Tính số tiền trung bình trong hoá đơn và tips mỗi giới tính khi có hút thuốc và không hút thuốc chi ra cho 1 bữa ăn tối tại nhà hàng theo thống kê trong tips_df.
tips_df[tips_df['time'] == 'Dinner'].groupby(['sex','smoker'])[['total_bill','tip']].mean()
Bài tập:
- Tổng doanh thu của nhà hàng thời gian dùng bữa của khách hàng theo số liệu thống kế trong
tips_df. - Tổng doanh thu không tính tips của nhà hàng theo thời gian dùng bữa với riêng khách hàng không hút thuốc vào cuối tuần (thứ 7, chủ nhật).
Bài giải:
- Tổng doanh thu của nhà hàng thời gian dùng bữa của khách hàng theo số liệu thống kế trong
tips_df.
tips_df.groupby('time').total_bill_tip.sum()
- Tổng doanh thu không tính tips của nhà hàng theo thời gian dùng bữa với riêng khách hàng không hút thuốc vào cuối tuần (thứ 7, chủ nhật).
tips_df[(tips_df['smoker'] == 'No') & ((tips_df['day'] == 'Sat') | (tips_df['day'] == 'Sun'))].groupby('time').total_bill.sum()
2.3.2 Pivot
Nếu như bạn đã từng làm việc với Excel chắc hẳn không lạ gì với Pivot Table. Tương tự như Pivot Table trong Excel, Pandas hỗ trợ ta tổng hợp, trích lọc, phân tích dữ liệu dễ dàng và nhanh chóng với pivot_table().
pivot_table() khá tương đồng với groupby() bởi cùng theo nguyên lý split-apply-combine giống nhau, tuy nhiên dữ liệu sẽ được phân tích và tổng hợp dưới với pivot_table() đa chiều (mulitdimensional) chứ không phải là một chiều như groupby().
Một số tham số cần lưu ý:
- data: DataFrame
- values (optional): cột để tổng hợp
- index: cột, Group hoặc mảng. Nếu mảng được truyền vào thì phải có độ dài bằng với dữ liệu
- columns: cột, Group hoặc mảng. Tương tự như index
- aggfunc: (default: mean): hàm tổng hợp dữ liệu
- fill_value: giá trị được điền vào các ô dữ liệu NA (sau khi đã tính toán)
- margins: (bool, default: False). Thêm một cột tính tất cả các giá trị của các cột còn lại theo hàm tổng hợp
- margins_name (string, default: 'All'): Tên của cột margins
- dropna: (bool, default: False). Bỏ đi các hàng có chứa NA
- observed: (bool, default: False). Chỉ áp dụng nếu tất cả các nhóm dữ liệu đều là Categoricals.Nếu là True: chỉ hiển thị các giá trị quan sát được cho các nhóm phân loại. Nếu là False: hiển thị tất cả các giá trị cho các nhóm phân loại.
Thực hành: Tính trung bình số tiền mỗi giới tính trả khi ăn tại nhà hàng theo thống kê trong tips_df.
tips_df.pivot_table(values='total_bill_tip', index='sex', aggfunc='mean')
Thực hành: Tính tổng số tiền nhà hàng thu được không kể tips các ngày trong tuần theo bữa ăn được thống kê trong tips_df.
tips_df.pivot_table(values='total_bill', index='day', columns='time',aggfunc='sum')
2.4. Hợp nhất dữ liệu (Merge, Concat)
2.4.1. Merge
Pandas có đầy đủ tính năng, hiệu suất cao trong hoạt động in-memory join rất giống với SQL thông qua hàm merge(). Dưới đây là 1 số so sánh giữa phương pháp sử dụng trong Pandas và trong SQL và hình ảnh minh hoạ để có thể thấy rõ sự tương đồng này.
| Merge methods | SQL Join Name | Meaning | _merge |
|---|---|---|---|
| left | LEFT OUTER JOIN | Chỉ sử dụng keys bên trái | left_only |
| right | RIGHT OUTER JOIN | Chỉ sử dụng keys bên phải | right_only |
| outer | FULL OUTER JOIN | Sử dụng keys của cả 2 dataframes | both |
| inner | INNER JOIN | Chỉ sử dụng keys giao nhau của 2 dataframes | both |

Dưới đây là 1 số ví dụ giúp bạn làm quen với cách sử dụng hàm với các tham số trên.
left = tips_df.head(6)[['total_bill','tip']].reset_index()
right = tips_df.loc[4:8][['tip','sex']].reset_index()
left.merge(right, on=['index','tip'], how='left')
left.merge(right, on=['index','tip'], how='right')
left.merge(right, on=['index','tip'], how='inner')
left.merge(right, on=['index','tip'], how='outer')
2.4.2 Concat
Trong thực tế, ta có thể làm việc với các dữ liệu có cấu trúc cùng 1 format (bao gồm các cột tương đồng nhau) nhưng được chia nhỏ thành các file khác nhau. Để có thể thuận lợi đánh giá được dữ liệu 1 cách tổng quan nhất, ta cần nối các dữ liệu có cấu trúc này với nhau và Pandas hỗ trợ ta đắc lực thông qua hàm pd.concat(). Dưới đây là 1 ví dụ về cách thức hàm hoạt động.
pd.concat([tips_df.head(3),tips_df.tail(3), tips_df.sample(3)[['total_bill','tip','sex']]])
Trong bài sau, chúng ta sẽ cùng nhau tìm hiểu cách trực quan hoá dữ liệu thông qua 1 số thư viện phổ biến như Matplotlib, Seaborn.